【英文长推】为什么选择 NEAR 来实现数据可用性?
认为 NEAR 只是 L1 是错的,NEAR 最适合解决以太坊生态系统的可扩展性和碎片化问题:自 2020 年 10 月主网启动以来,4 个分片的正常运行时间达 100%;已注册账户数超过 1 亿,月活跃账户数 (MAA) 达 1600 万。支持如此多的活动和可扩展性无疑需要高数据可用性和低成本数据发布,以便应用程序扩展到全球主流采用的水平。 NEAR DA 为这一可扩展性问题提供了解决方案。凭借易于实施和不断提高效率的简单架构,以及 Web3 所有网络中最便宜的交易费用,NEAR DA 的速度令人难以置信且具有成本效益。数据可用性和 NEAR DA 在链抽象中也发挥着重要作用。由于零知识技术通过状态证明实现了跨链安全的统一,结算数据将更容易从不同的网络获取。 有人可能会问 NEAR DA 的下一步是什么,这就是数据可用性分片的用武之地。NEAR Protocol 工程团队最近宣布转向无状态验证,即分片的下一阶段。这将进一步降低某些类型的验证器(chunk 验证器)的硬件要求,并将状态移至内存中。这意味着分片数量将会增加,从而大大提高 NEAR Protocol 的整体吞吐量。 虽然 NEAR 已经很快,4 个分片每个速度为 4 MB/s,但扩展到 n 个分片意味着使用 NEAR 的 rollups 将不必竞争区块空间。随着 NEAR Protocol 将分片数量增加到 n,单个分片必须存储的数据量会减少。最终,理论上,NEAR Protocol 上的每个账户都可能成为自己的分片。虽然数据可用性分片仍处于研究开发阶段,但它显示了 NEAR Protocol 为多种构建者和生态系统提供的主要优势。【原文为英文】\n原文链接
温馨提示:
快链头条登载此文本着传递更多信息的缘由,并不代表赞同其观点或证实其描述。
文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。
7*24小时快讯
热门资讯

熊市生存指南:L2 还有哪些潜在空投机会?
2022-05-13 12:47
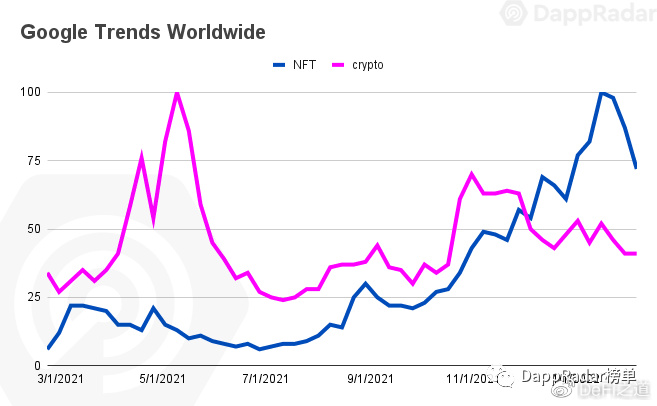
鲸鱼报告:解密知名NFT收藏家的交易模式
2022-02-28 16:56

目前的市场环境能否支撑比特币再次走牛?
2022-04-19 18:10

除了Coinlist,你还应该知道的打新平台
2022-03-01 13:37
最新活动

2024年比特币峰会将在香港召开
2024-05-09 00:00

Bitcoin Devcon大会将于5月7日至8日在香港举办
2024-03-27 17:21

「Deep in Labs 」DePIN Demo Day将于4月28日举行
2024-03-28 11:59
TOKEN2049 Dubai
2024-04-18 13:00

